ColdFusion MX и XML: Анализ XML
Получение файла
Технологии анализа XML могут быть разделены на 2 категории:
- обработчик (парсер) по элементам (SAX - Simple API for XML)
- обработчик (парсер) структуры дерева (DOM – Document Object Model - и JDOM).
Инструменты CFMX используют вторую категорию. С помощью парсера весь XML файл анализируется и помещается в память. Затем текстовая версия XML преобразуется в объектную модель, которую можно просматривать с помощью структуры объекта парсера. Большинство парсеров структуры дерева требуют изучения имен и методов различных объектов программ, чтобы находить и считывать данные. В CFMX XML документ распознается и ведет себя в большинстве случаев как переменная. Если вы знаете, как использовать структуры и массивы, то вы уже знаете, большинство из того, что вам понадобиться в работе с XML.
Первым шагом следует прочесть содержимое XML файла в переменную. Для этого мы используем уже знакомые инструменты. Если файл доступен через локальную файловую систему, прочитаем его тегом <cffile>:
Если файл на удаленном сервере, то используем тег <cfhttp>:
Используемый в этой статье XML файл такой:
Объект XML документа
Преобразование содержимого XML файла в структуру объекта занимает всего одну строку кода. Для этого мы используем функцию XMLParse(), которая знает, как создать XML объект из текстовых переменных. Вот код:
Вот и все. Теперь мы готовы считывать данные. Если вы хотите посмотреть полученную структуру XML объекта, то выведите ее на экран с помощью тега <cfdump>:
Примерную структуры мы можем посмотреть на рисунке 1.
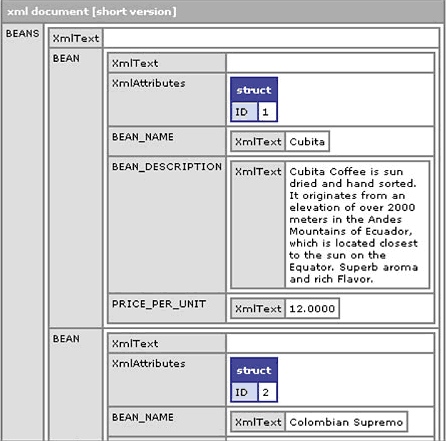
Рисунок 1. Краткий вид XML объекта.
Обратите внимание, что тег <cfdump> пишет в заголовке "xml document [short version]". Существует два вида предоставления содержимого XML. По-умолчанию, тег <cfdump> предоставляет укороченный вариант (называемый "Основная" структура), которые интересен нам в большинстве случаев. Чтобы посмотреть более подробную версию (или DOM), то щелкните мышкой по заголовку.
Считывание данных
Существует два способа обращаться к частям XML объекта. Первый способ – подход через DOM. При этом подходе XML документ содержит вложенный элемент XMLRoot, который относится к корневому элементу XML файла. Этот и любой другой элементы имеют набор вложенных объектов с фиксированными именами. Наиболее часто используемые вложенные объекты это:
| XMLName |
Имя элемента |
| XMLText |
Вложенный в элемент текст и ветви CDATA |
| XMLComment |
Вложенный в элемент комментарий |
| XMLAttributes |
Структура, содержащая атрибуты элементов |
| XMLChildren |
Массив вложенных элементов |
Просмотрите простой фрагмент XML:
Чтобы получить значение элемента "ColdFusion", длинная форма обращения будет такой:
xmlDoc.XmlRoot.XmlChildren[1].XmlText
Чтобы получить значение атрибута "version", код будет такой:
xmlDoc.XmlRoot.XmlChildren[1].XmlAttributes.version
Такой синтаксис немного труден к восприятию и порождает некоторые проблемы. Например, если массив XML Children содержит элементы с разными именами, то придется циклически проходить по всем элементам в поиске нужного элемента. Поэтому CFMX предоставляет упрощенную систему обращения к элементам. Упрощенный синтаксис похож на тот, который мы используем в работе со структурами или массивами.
К каждому уникальному элементу можно обращаться по его имени, как к элементу структуры. Если вы хотите получить значение текста в уникальном элементе "ColdFusion" и вы знаете имя элемента заранее, то код будет такой:
xmlDoc.Software.ColdFusion.XmlText
А чтение значения атрибута будет таким:
xmlDoc.Software.ColdFusion.XmlAttributes.version
Если вы не знаете имена элементов или атрибутов заранее, то вместо точечного синтаксиса используйте синтаксис массивов:
xmlDoc.Software[softwarename].XmlAttributes[attributename]
Обратите внимание: Поскольку технология XML чувствительна к регистру, то и ColdFusion обращается к именам элементов и атрибутов с учетом их регистра.
Циклический проход по элементам
Если в элементе присутствуют более одного вложенного элемента с одним и тем же именем, то мы можем обращаться к ним как к массиву элементов, где имя массива совпадает с именем этих элементов.
Для файла Beans.xml вывод списка имен кофейных зерен будет таким:
Более красивый вывод информации из XML объекта может быть таким:
Результат выполнения этого кода приведен на рисунке 2.
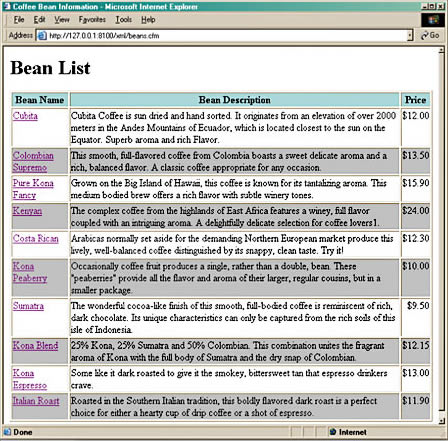
Рисунок 2. Отображение XML данных в виде HTML.
Поиск XML данных
Также как и в реляционных базах данных, мы можем делать запрос к определенным элементам или наборам элементов. Для этого в CFMX есть функция XMLSearch(), которая принимает два аргумента: XML объект и выражение XPath. XPath – это мощный язык запросов к XML структурам, который представлен во многих XML технологиях, включая XSLT, XPointer, и XML базах данных.
Вот пример XPath запроса, который возвращает одни элемент Bean иза нашего файла Bean.xml, основываясь на атрибуте ID в элементе BEAN:
Этот образец XPath означает: найти элементы с именем BEAN, где атрибут ID равен 1. Двойной слэш ("//") означает, что элемент BEAN может быть в любом месте XML иерархии. XMLSearch() возвращает массив элементов, которые соответствуют образцу. В этом примере, предполагая, что каждый ID у BEAN уникален, мы получим массив с одним значением: элемент Bean с ID равным 1.
В XPath есть гораздо больше команд и этот язык достоин того, чтобы его изучать.
Получив массив, у нас есть только один простой способ обращаться к элементу:
#aBeans[1].Bean_Name.XmlText#
Более наглядный пример поиска и отображения данных показан в этом коде:
Завершаем приложение
Описанные выше два файла: bean_list.cfm и bean_detail.cfm – отображают, соответственно, списко всех XML элементов и детальную информацию об одном конкретном элементе. Последним контрольным файлом будет beans.cfm, который будет вызывать список или детали, в зависимости от полученного ID через URL.
Ограничения
ColdFusion инструменты анализа XML имеют некоторые ограничения:
- Работа с файлами большого размера: Как анализатор дерева, ColdFusion должен выделить достаточный объем памяти, для хранения структуры всего XML файла. В результате попытки чтения очень больших XML файлов, могут возникнуть проблемы с производительностью. Если вы столкнетесь с такими файлами, то вам понадобится использовать один из стандартных SAX анализаторов.
- Проверка правильности: Текущая версия XML анализатора не осуществляет правильность структуры в соответствии с DTD (Document Type Definition) или XML Schema. Но если DTD объявлен, то должен быть доступен анализатору. Тут могут быть неприятности: анализатор считывает из текстовой переменной, а не из файла напрямую, поэтому он не может найти DTD файлы, на которые указывает относительный адрес. Например, объявление <!DOCTYPE BEANS SYSTEM "beans.dtd"> всегда неудачно, т.к. не предоставлен полный путь к файлу. Это следует подправить, указав более полный путь к файлу, либо удалив объявление вообще.
Источник: ColdFusion MX and XML: Parsing XML Part 1
© 2002-2005 г. Вадим Пушкарев